Taking screenshots of web pages seems like a simple task until you actually try
to do it. I learned this the hard way when I decided to capture a long Reddit
thread. What started as a straightforward browser.TakeImage() call turned into
a deep dive into browser viewports, dynamic content loading, and not
running out of memory.
In this article, I’ll share my journey from a naive approach to a robust solution. We’ll explore common pitfalls and how to avoid them using the r/dotnet subreddit as our test subject. By the end, you’ll have a solid understanding of how to capture web pages effectively, even when they’re filled with dynamic content and infinite scrolling.
Taking a simple screenshot
Let’s start with the most basic approach: capturing a screenshot without any special handling. In DotNetBrowser, this is as simple as:
var image = browser.TakeImage();
var bitmap = ToBitmap(image);
bitmap.Save("screenshot.png", ImageFormat.Png);
Since DotNetBrowser returns the raw bitmap, we need a utility method
to convert it to System.Drawing.Bitmap for standard .NET operations:
public static Bitmap ToBitmap(DotNetBrowser.Ui.Bitmap bitmap)
{
var width = (int)bitmap.Size.Width;
var height = (int)bitmap.Size.Height;
var data = bitmap.Pixels.ToArray();
var bmp = new Bitmap(width, height, PixelFormat.Format32bppRgb);
var bmpData =
bmp.LockBits(new Rectangle(0, 0, bmp.Width, bmp.Height),
ImageLockMode.WriteOnly, bmp.PixelFormat);
Marshal.Copy(data, 0, bmpData.Scan0, data.Length);
bmp.UnlockBits(bmpData);
return bmp;
}
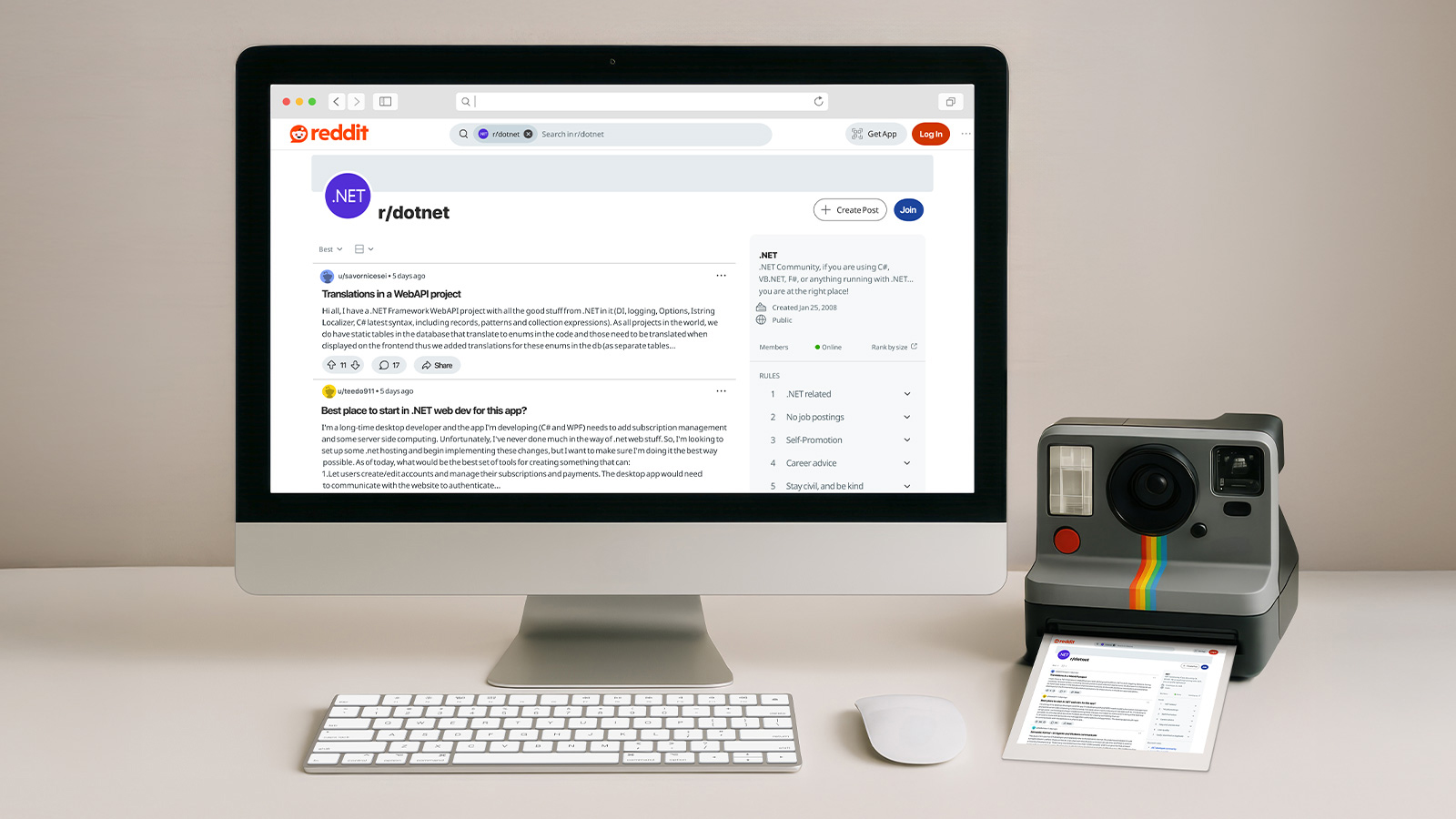
Running this code gives us our first screenshot:
A screenshot made with a simple TakeImage() call.
But there’s an immediate problem: we captured a small part of the page.
That happens because the TakeImage() method captures only what’s visible in
the browser’s viewport. And the default size of the viewport is not big enough.
Taking screenshot of a whole page
Let’s find the dimensions of the page, resize the browser to fit them,
and try again. We can determine the dimensions of the page using JavaScript
by taking the size of either document or document.documentElement,
whichever is bigger:
var widthScript = @"Math.max(
document.body.scrollWidth,
document.documentElement.scrollWidth)";
var heightScript = @"Math.max(
document.body.scrollHeight,
document.documentElement.scrollHeight)";
Then we resize the browser to match these dimensions:
var frame = browser.MainFrame;
var width = frame.ExecuteJavaScript<double>(widthScript).Result;
var height = frame.ExecuteJavaScript<double>(heightScript).Result;
browser.Size = new Size((uint)width, (uint)height);
var image = browser.TakeImage();
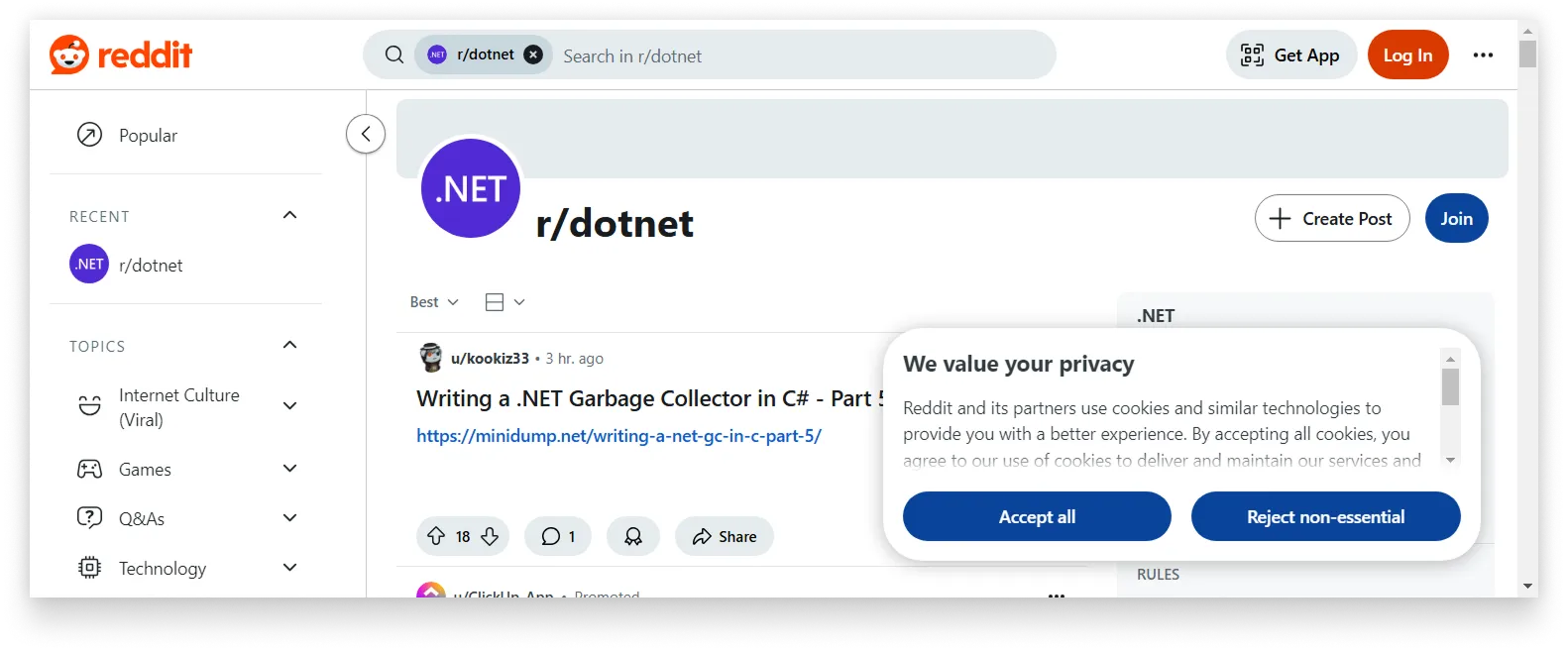
Here’s what we get with this improved approach:
A screenshot is bigger, but the content is still loading. See full image
And we’ve hit another snag: the page isn’t fully loaded. This is happening because we capture the browser immediately after the resize, not letting the browser load and render all the content. We can see this in action with the loading indicator at the bottom of the page.
Let’s add a pause:
browser.Size = new Size((uint)width, (uint)height);
// An arbitrary number found by trial and error.
Thread.Sleep(2000);
var image = browser.TakeImage();
And try again:
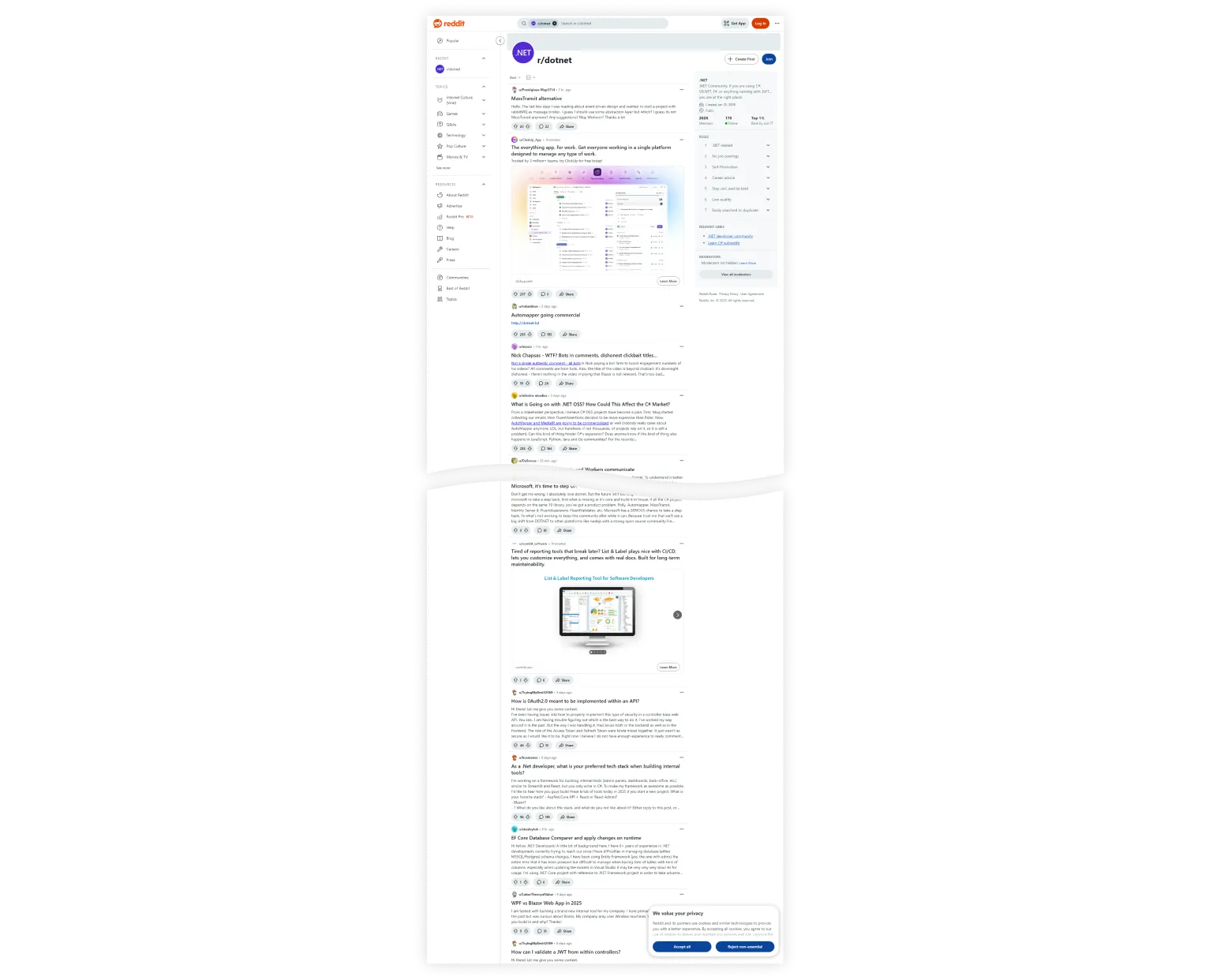
A big screenshot with all the content. See full image
Finally, a proper screenshot! But a bitmap object gets quite large, and Chromium needs lots of resources to render a big viewport, which is not practical. We can do better.
Taking screenshot in segments
With the previous approach, the browser renders the entire page at once, and the resulting bitmap is passed to the .NET process memory. When dealing with long pages, that can quickly exhaust system resources, particularly RAM.
Instead of trying to capture the entire page at once, we can break it down into smaller, manageable pieces:
- Take multiple screenshots of smaller page segments.
- Scroll between each capture.
- Stitch the segments together into a final image.
Here’s how we can implement this approach:
// Reddit is infinite, so let's fix the number of screenshots.
var numberOfShots = 15;
var viewportHeight = 1000;
browser.Size = new Size((uint)Width, (uint)viewportHeight);
var capturedHeight = 0;
for (var count = 0; count < numberOfShots; count++)
{
capturedHeight += viewportHeight;
frame.ExecuteJavaScript($"window.scrollTo(0, {capturedHeight})").Wait();
// An arbitrary pause to wait for the content to load.
Thread.Sleep(500);
var image = browser.TakeImage();
var bitmap = ToBitmap(image);
bitmap.Save($"screenshot-{count:D3}.png", ImageFormat.Png);
}
In a real app, we would stitch the segments in an asynchronous job on another server. But for simplicity, we will use this helper function right away:
public static Bitmap MergeBitmapsVertically(List<Bitmap> bitmaps)
var files = Directory.GetFiles("/path/to/directory", "*.png")
.OrderBy(Path.GetFileName)
.ToArray();
var images = files.Select(f => Image.FromFile(f)).ToArray();
int width = images.Max(img => img.Width);
int totalHeight = images.Sum(img => img.Height);
using var merged = new Bitmap(width, totalHeight);
using (var g = Graphics.FromImage(final))
{
int y = 0;
foreach (var img in images)
{
g.DrawImage(img, 0, y);
y += img.Height;
}
}
merged.Save("merged.png");
}
Let’s see what we’ve got:
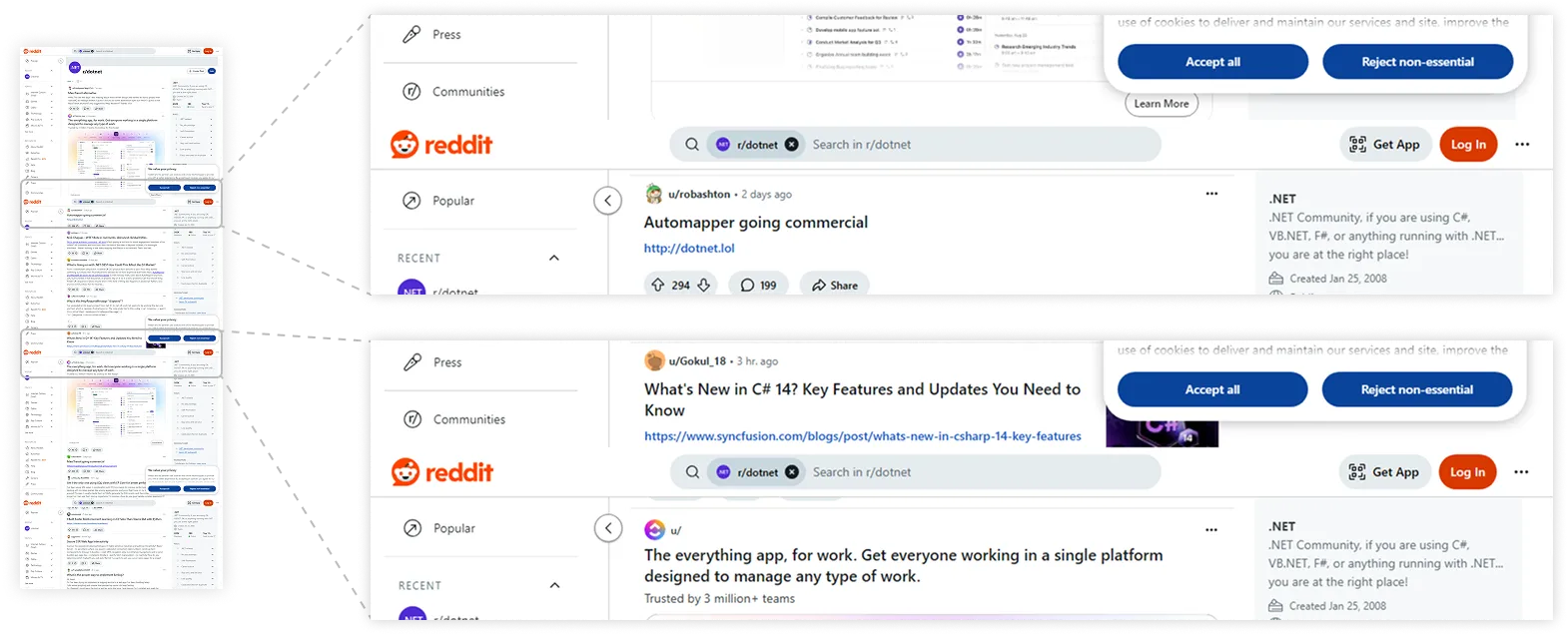
Merged screenshot segments have repeating elements. See full image
Another twist, another problem: the header and navigation sidebars are showing up in every segment, which definitely isn’t how a screenshot should look!
Dealing with fixed elements
When we scroll the page, the fixed elements like header and sidebars stay put. But when taking a screenshot in segments, we want fixed elements to appear only in the first segment.
Let’s find such elements by the position CSS property and hide them:
var removeFixedElements =
@"(() => {
document.querySelectorAll('*').forEach(el => {
const pos = getComputedStyle(el).position;
if (pos === 'fixed' || pos === 'sticky') {
el.style.display = 'none';
}
});
})()";
for (var count = 0; count < numberOfShots; count++)
{
// Only removed fixed elements starting with the second screenshot,
// to keep the header and navigation visible on the first one.
if (count == 1)
{
frame.ExecuteJavaScript(removeFixedElements).Wait();
}
// Proceed to taking the screenshot.
}
Another fixed element we often see is a cookie consent dialog. As each site implements this dialog differently, we need to handle it on a case-by-case basis.
For Reddit, we can identify and hide the cookie dialog using the following code:
var removeCookieScreen =
@"(() => {
const dialog = document.querySelector('reddit-cookie-banner');
if (dialog) {
dialog.style.display = 'none';
}
})()";
frame.ExecuteJavaScript(removeCookieScreen).Wait();
Finally, we have a proper screenshot that we captured in a memory-efficient way.
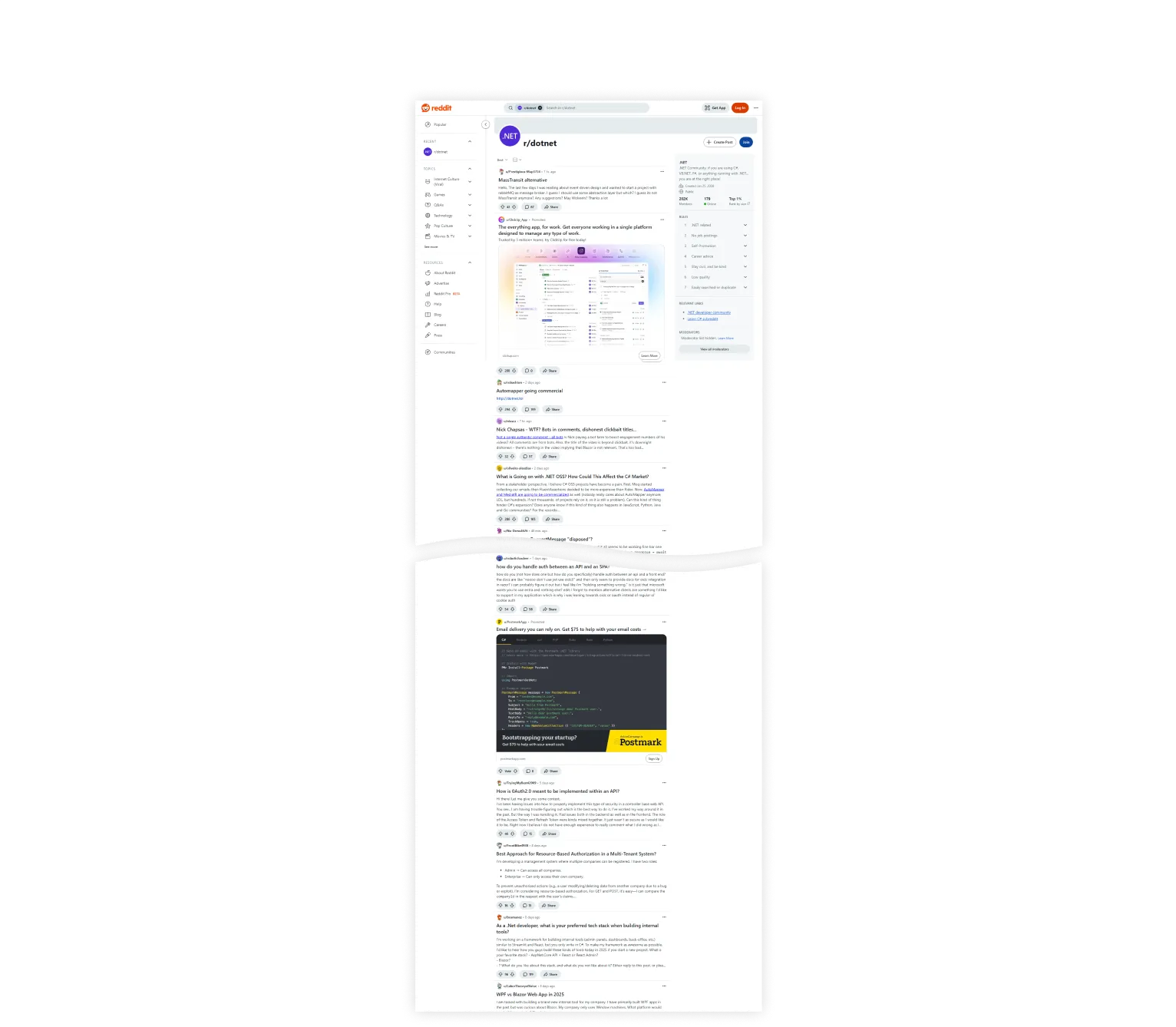
A clean, complete screenshot. See full image
Conclusion
What started as a simple browser.TakeImage() call turned into a complicated
solution with thousands of potential nuances to consider.
We tackled several challenges:
- Capturing a page in one go.
- Capturing a big page in segments.
- Tackling fixed elements and cookie dialogs.
- Optimizing memory usage and practicality.
The suggested approach is not universal by any means. Every web page is a unique beast, and good screenshot software is all about the unique corner cases it covers. And yet, it describes everything you need to know to take screenshots of web pages with DotNetBrowser.
Sending…
Sorry, the sending was interrupted
Please try again. If the issue persists, contact us at info@teamdev.com.
Your personal DotNetBrowser trial key and quick start guide will arrive in your Email Inbox in a few minutes.