
There is a lot of data on the Internet now. Often, it needs to be extracted and analyzed for various marketing research and business decision-making purposes. When needed, it should be done quickly and efficiently.
Why does one need to collect and analyze data? It may be necessary for a variety of reasons:
- Conducting a website audit;
- Aggregating data from online stores;
- Training set preparation for neural networks;
- Monitoring reviews in social networks, news feeds, blogs;
- Analyzing the website content, such as identifying dead links on the site, etc.
The data isn’t limited to text only; it can be images, videos, tables, various files, etc. One may need to extract links and text, search by keywords or phrases, collect pictures, etc.
Another vital task is to monitor the site’s health, check whether there are no dead links and whether the site is generally available.
All this requires ready-to-go tools.
Existing solutions
The most common approach to collecting and analyzing data is sending a request to a web server, receiving and processing the response in HTML. We need to parse HTML and extract the necessary information.
However, modern web pages actively use JavaScript, and the content is loaded or formed dynamically on many pages. It is not enough to just get a response from the web server — as it may be just a bootstrap page with lots of JavaScript, execution of which generates the necessary content.
How to use the web browser capabilities?
Websites are created for people. People visit websites through web browsers.
How about using the web browser to collect data? It would remove many limitations of the approach of sending requests to the web server. After all, you need to log in on some sites and perform several actions on the page to get the result. Somewhere it would be the best if we had control over browser’s User-Agent, so that the server doesn’t think that we are a robot. It also helps to receive desktop-oriented content, not just some stripped version for mobile devices.
In this article, we will look at the approach on collecting data using the capabilities of a web browser. In particular, we will collect all the links on the specified site and check whether there are any broken ones among them, i.e., links that lead to unavailable pages for any reason. We will do this using the capabilities of the Chromium browser via the JxBrowser library.
JxBrowser is a commercial Java library that allows you to use the powers of Chromium in commercial Java applications. It is helpful for companies that develop and sell software solutions created using Java technology or need an advanced and reliable web browser component for Java applications created for internal needs.
What should you do before the start?
What are the points we should consider before we start designing the solution and writing the code? We need to start from a particular page of the website. It can be a home page or just a website address.
On the page, we should find links to other pages. Links may lead to other websites (external) and the same website pages (internal). Also, a link doesn’t always lead to another page. Some of them take visitors to a section of the same page (such links usually start with a #). Some of them aren’t links per se, but rather emailing action shortcuts — mailto:.
As links may be circular, we need to be especially careful. To deal with circular references properly, we need to remember the pages we have already visited.
It is also crucial to check that the page to which the link leads is unavailable, and it is desirable to get an error code explaining why it is out of reach.
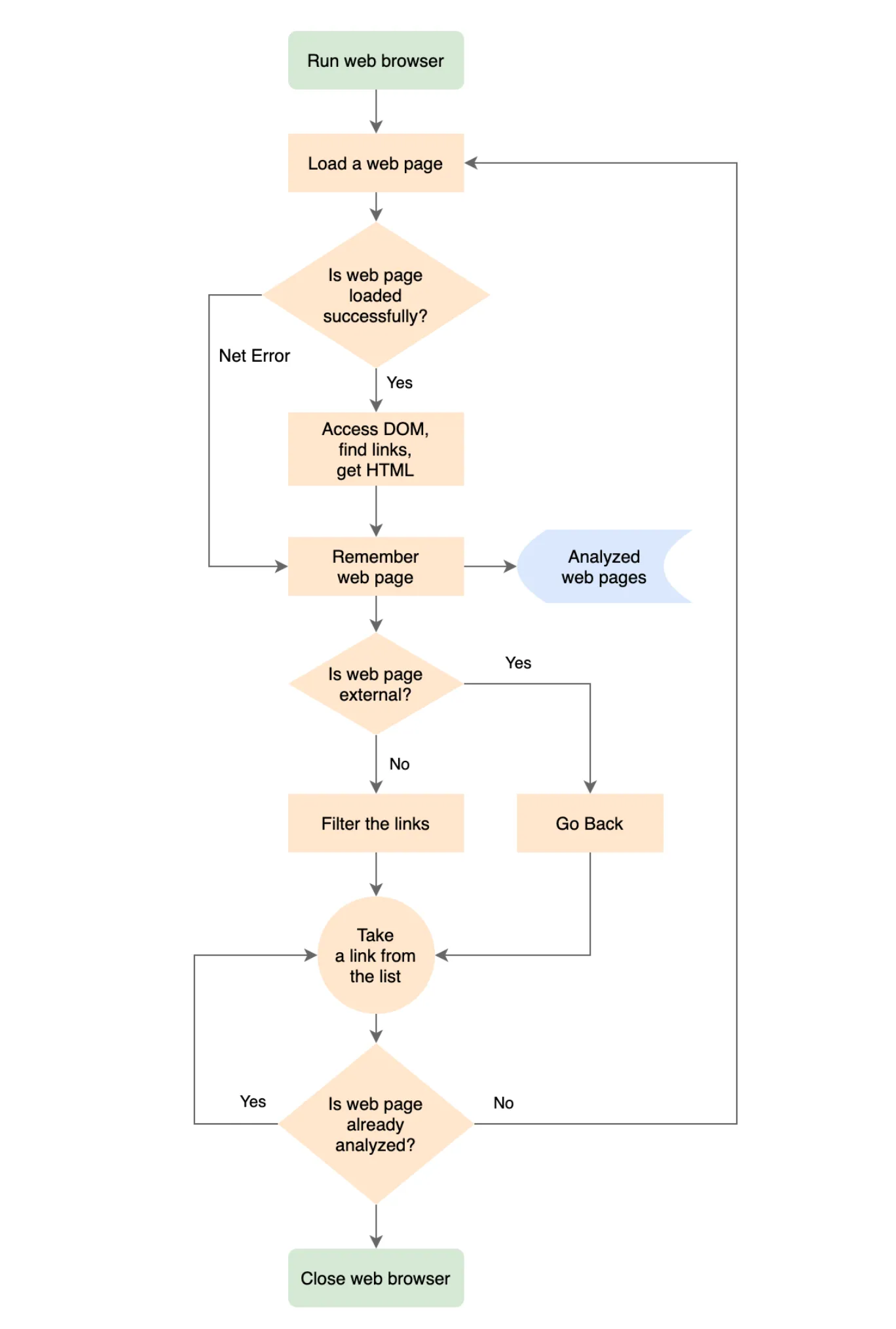
The algorithm
Given all the of the information above, let’s try to think about how a program based on a web browser could work.
- Launch the web browser.
- Load the necessary web page.
- If the page is loaded, access its DOM and find all the anchor HTML elements. For each of them, obtain the HREF value of each component. This way, we will get all the links on the page.
- If the page didn’t load, remember the web server’s error for the page.
- Remember the processed page.
- If the page belongs to our website, filter the links; remove those that do not interest us, such as links to subsections of the page or mailto:.
- Go through the received links list.
- For each page from the list, follow the steps starting from p. #1.
- If it is an external page, then remember it but do not analyze its links. We are only interested in the links on the pages of our website.
- After we deal with all the discovered pages, we complete our navigation.
- Close the web browser.
- Go through all the analyzed pages and find those having broken links.
Below is the algorithm of the program in the flowchart form.
Implementation
Let’s look at how we can implement the main stages.
Starting a web browser:
Engine engine = Engine.newInstance(OFF_SCREEN);
Browser browser = engine.newBrowser();
Loading a web page:
browser.navigation().loadUrlAndWait(url, Duration.ofSeconds(30));
Gaining DOM access and searching for links:
browser.mainFrame().flatMap(Frame::document).ifPresent(document ->
// Collect the links by analyzing the HREF attribute of
// the Anchor HTML elements.
document.findElementsByTagName("a").forEach(element -> {
try {
String href = element.attributeValue("href");
toUrl(href, browser.url()).ifPresent(
url -> result.add(Link.of(url)));
} catch (IllegalStateException ignore) {
// DOM of a web page might be changed dynamically
// from JavaScript. The DOM HTML Element we analyze,
// might be removed during our analysis. We do not
// analyze attributes of the removed DOM elements.
}
}));
Getting the HTML page:
/**
* Returns a string that represents HTML of
* the currently loaded web page.
*/
private String html(Browser browser) {
AtomicReference<String> htmlRef = new AtomicReference<>("");
browser.mainFrame().ifPresent(frame ->
htmlRef.set(frame.html()));
return htmlRef.get();
}
Example of the leading class that analyzes a website.
package com.teamdev.jxbrowser.examples.webcrawler;
import static com.google.common.base.Preconditions.checkNotNull;
import static com.teamdev.jxbrowser.engine.RenderingMode.OFF_SCREEN;
import com.google.common.collect.ImmutableSet;
import com.teamdev.jxbrowser.browser.Browser;
import com.teamdev.jxbrowser.engine.Engine;
import com.teamdev.jxbrowser.engine.EngineOptions;
import java.io.Closeable;
import java.util.HashSet;
import java.util.Optional;
import java.util.Set;
/**
* A web crawler implementation that is based on JxBrowser that
* allows discovering and analyzing the web pages, accessing
* their DOM and HTML content, finding the broken links on a web
* page, etc.
*/
public final class WebCrawler implements Closeable {
/**
* Creates a new {@code WebCrawler} instance for the given
* target {@code url}.
*
* @param url the URL of the target web page the crawler
* will start its analysis
* @param factory the factory used to create a {@link
* WebPage} instance for the internal and
* external URLs
*/
public static WebCrawler newInstance(String url,
WebPageFactory factory) {
return new WebCrawler(url, factory);
}
private final Engine engine;
private final Browser browser;
private final String targetUrl;
private final Set<WebPage> pages;
private final WebPageFactory pageFactory;
private WebCrawler(String url, WebPageFactory factory) {
checkNotNull(url);
checkNotNull(factory);
targetUrl = url;
pageFactory = factory;
pages = new HashSet<>();
engine = Engine.newInstance(
EngineOptions.newBuilder(OFF_SCREEN)
// Visit the web pages in the Chromium's
// incognito mode.
.enableIncognito()
.build());
browser = engine.newBrowser();
}
/**
* Starts the web crawler and reports the progress via the
* given {@code listener}. The time required to analyze web
* site depends on the number of discovered web pages.
*
* <p>This operation blocks the current thread execution
* until the crawler stops analyzing the discovered web pages.
*
* @param listener a listener that will be invoked to report
* the progress
*/
public void start(WebCrawlerListener listener) {
checkNotNull(listener);
analyze(targetUrl, pageFactory, listener);
}
private void analyze(String url, WebPageFactory factory,
WebCrawlerListener listener) {
if (!isVisited(url)) {
WebPage webPage = factory.create(browser, url);
pages.add(webPage);
// Notify the listener that a web page
// has been visited.
listener.webPageVisited(webPage);
// If it is an external web page, do not go
// through its links.
if (url.startsWith(targetUrl)) {
webPage.links().forEach(
link -> analyze(link.url(), factory,
listener));
}
}
}
/**
* Checks if the given {@code url} belongs to an already
* visited web page.
*/
private boolean isVisited(String url) {
checkNotNull(url);
return page(url).orElse(null) != null;
}
/**
* Returns an immutable set of the web pages that are already
* analyzed by this crawler.
*/
public ImmutableSet<WebPage> pages() {
return ImmutableSet.copyOf(pages);
}
/**
* Returns an {@code Optional} that contains a web page
* associated with the given {@code url} or an empty options
* if there is no such web page.
*/
public Optional<WebPage> page(String url) {
checkNotNull(url);
for (WebPage page : pages) {
if (page.url().equals(url)) {
return Optional.of(page);
}
}
return Optional.empty();
}
/**
* Releases all allocated resources and closes the web
* browser used to discover and analyze the web pages.
*/
@Override
public void close() {
engine.close();
}
}
The complete program code is available on GitHub.
Results
If we compile and run the program, we should get the following output:
https://teamdev.com/jxbrowser [OK]
https://teamdev.com/about [OK]
https://teamdev.com/jxbrowser/docs/guides/dialogs/ [OK]
https://teamdev.com/jxcapture [OK]
https://teamdev.com/jxbrowser/api/7.13/com/teamdev/jxbrowser/view/javafx/BrowserView.html [OK]
https://spine.io [OK]
https://jxbrowser.support.teamdev.com/support/tickets [OK]
https://sos-software.com [OK]
...
Dead or problematic links:
https://www.teamdev.com/jxbrowser
https://www.shi.com CONNECTION_TIMED_OUT
http://www.comparex-group.com ABORTED
http://www.insight.com NAME_NOT_RESOLVED
https://www.swnetwork.de/swnetwork ADDRESS_UNREACHABLE
...
Process finished with exit code 0
Nuances, problems, and solutions
Here are some nuances encountered during the implementation and testing of this solution on various websites.
Many web servers are protected from DDoS attacks, and frequent requests are rejected with the error code ABORTED. To remove the load from the website and conduct a “polite” analysis, you need to use a timeout. In the program, we use a delay of 500 ms. Unfortunately, even with this delay, the web server rejects our requests.
We don’t give up and try to load the page at different intervals:
/**
* Loads the given {@code url} and waits until the web page
* is loaded completely.
*
* @return {@code true} if the web page has been loaded
* successfully. If the given URL is dead, or we didn't manage
* to load it within 45 seconds, returns {@code false}.
*
* @implNote before every navigation we wait for {@link
* #NAVIGATION_DELAY_MS} because web server may abort often
* URL requests to protect itself from DDoS attacks.
*/
private NetError loadUrlAndWait(Browser browser, String url,
int navigationAttempts) {
// All our attempts to load the given url were rejected.
// We give up and continue processing other web pages.
if (navigationAttempts == 0) {
return NetError.ABORTED;
}
try {
// Web server might abort often URL requests to
// protect itself from DDoS attack. Use a delay
// between URL requests.
long timeout = (long) NAVIGATION_DELAY_MS
* navigationAttempts;
TimeUnit.MILLISECONDS.sleep(timeout);
// Load the given URL and wait until web page
// is loaded completely.
browser.navigation()
.loadUrlAndWait(url, Duration.ofSeconds(30));
} catch (NavigationException e) {
NetError netError = e.netError();
if (netError == NetError.ABORTED) {
// If web server aborts our request, try again.
return loadUrlAndWait(browser, url,
--navigationAttempts);
}
return netError;
} catch (TimeoutException e) {
// Web server did not respond within 30 seconds (
return NetError.CONNECTION_TIMED_OUT;
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return NetError.OK;
}
The web server can make a redirect when loading the page. When we load one address, we get to another one. We can remember both addresses, but it’s vital to stop at remembering only the requested address in the application.
The web server may not respond to some requests at all. Therefore, when loading the page, we need to use the timeout to wait for the download. If the page was not loaded during this timeout, you would mark the page as unavailable with the error CONNECTION_TIMED_OUT.
On some web pages, the DOM model may change immediately after the page loads. Therefore, when analyzing the DOM model, we have to handle the situation when some DOM elements may not be traversing the DOM tree.
browser.mainFrame().flatMap(Frame::document).ifPresent(document ->
// Collect the links by analyzing the HREF attribute of
// the Anchor HTML elements.
document.findElementsByTagName("a").forEach(element -> {
try {
String href = element.attributeValue("href");
toUrl(href, browser.url()).ifPresent(
url -> result.add(Link.of(url)));
} catch (IllegalStateException ignore) {
// DOM of a web page might be changed dynamically
// from JavaScript. The DOM HTML Element we analyze,
// might be removed during our analysis. We do not
// analyze attributes of the removed DOM elements.
}
}));
For sure there are many other website nuances in the analysis you may encounter. Fortunately, the web browser’s capabilities allow you to resolve most of them.
Conclusions
You can create a Java Crawler using a web browser, and due to our experience, this is a more natural way of website communication. Many SEO spider and Web Crawler tools in the professional software market have already been using these business-driven solutions based on the web browser’s capabilities for many years, proving the effectiveness of this approach.
You can experiment and try out new program turns. Download the source code from GitHub, make edits to suit your needs.
If you have any questions regarding this approach, just leave a comment down below. I will be happy to answer all your questions in detail.
Sending…
Sorry, the sending was interrupted
Please try again. If the issue persists, contact us at info@teamdev.com.
Your personal JxBrowser trial key and quick start guide will arrive in your Email Inbox in a few minutes.